Weblog von Beat Döbeli Honegger
Dies ist der private Weblog von Beat Döbeli Honegger
Categories
- 80 Annoyance
- 124 Biblionetz
- 8 Bildschirme
- 12 Bildungspolitik
- 8 DPM
- 11 Digital Immigrants
- 4 Elektromobil
- 28 GMLS
- 66 Gadget
- 58 Geek
- 7 GeoLocation
- 14 HandheldInSchool
- 109 Informatik
- 26 Information-Architecture (IA)
- 12 Kid
- 79 Medienbericht
- 135 Medienbildung
- 7 Modelle
- 30 OLPC
- 49 PH Solothurn
- 37 PHSZ
- 4 RechtUndInformatik
- 155 Schul-ICT
- 20 Scratch
- 7 SecondLife
- 107 Software
- 52 Tablet-PC
- 144 Veranstaltung
- 15 Video
- 61 Visualisierung
- 125 Wiki
- 21 Wissenschaft
- 7 Zeitschrift c't
Archive
- 5Jul 2026
- 4May 2026
- 3Apr 2026
- 3Mar 2026
- 4Feb 2026
- 8Jan 2026
- 7Dec 2025
- 2Nov 2025
- 2Oct 2025
- 2Sep 2025
- 1Aug 2025
- 4Jul 2025
- 1Jun 2025
- 5May 2025
- 5Sep 2024
- 1Aug 2024
- 2Jul 2024
- 1Jan 2024
- 1Dec 2023
- 1Sep 2023
- 2Jul 2023
- 1Jun 2023
- 1Mar 2023
- 1Feb 2023
- 1Jan 2023
- 1Jul 2022
- 1Jan 2022
- 1Oct 2021
- 1Sep 2021
- 1Jun 2021
- 2Apr 2021
- 1Feb 2021
- 1Nov 2020
- 3Sep 2020
- 2Jun 2020
- 1May 2020
- 1Apr 2020
- 2Mar 2020
- 1Feb 2020
- 2Jan 2020
- 1Dec 2019
- 1Nov 2019
- 1Oct 2019
- 4Sep 2019
- 1Jul 2019
- 1Jun 2019
- 3Apr 2019
- 1Mar 2019
- 3Jan 2019
- 1Dec 2018
- 1Nov 2018
- 1Oct 2018
- 1Aug 2018
- 4Jun 2018
- 2Dec 2017
- 3Nov 2017
- 2Oct 2017
- 5Sep 2017
- 4Jul 2017
- 1Jun 2017
- 1Apr 2017
- 1Jan 2017
- 3Dec 2016
- 3Nov 2016
- 1Oct 2016
- 3Sep 2016
- 1Aug 2016
- 1Jun 2016
- 3May 2016
- 4Apr 2016
- 3Mar 2016
- 4Jan 2016
- 3Dec 2015
- 3Nov 2015
- 2Oct 2015
- 3Sep 2015
- 4Aug 2015
- 3Jul 2015
- 5Jun 2015
- 8May 2015
- 5Apr 2015
- 6Mar 2015
- 5Feb 2015
- 6Jan 2015
- 6Dec 2014
- 10Nov 2014
- 5Oct 2014
- 9Sep 2014
- 3Aug 2014
- 3Jul 2014
- 6Jun 2014
- 4May 2014
- 8Apr 2014
- 6Mar 2014
- 5Feb 2014
- 4Jan 2014
- 6Dec 2013
- 7Nov 2013
- 15Oct 2013
- 4Sep 2013
- 8Aug 2013
- 7Jul 2013
- 13Jun 2013
- 5May 2013
- 5Apr 2013
- 8Mar 2013
- 4Feb 2013
- 10Jan 2013
- 9Dec 2012
- 7Nov 2012
- 10Oct 2012
- 7Sep 2012
- 8Aug 2012
- 7Jul 2012
- 4Jun 2012
- 3May 2012
- 9Apr 2012
- 9Mar 2012
- 1Feb 2012
- 6Jan 2012
- 9Dec 2011
- 3Nov 2011
- 10Oct 2011
- 13Sep 2011
- 4Aug 2011
- 8Jul 2011
- 7Jun 2011
- 8May 2011
- 7Apr 2011
- 4Mar 2011
- 3Feb 2011
- 7Jan 2011
- 7Dec 2010
- 10Nov 2010
- 11Oct 2010
- 9Sep 2010
- 6Aug 2010
- 6Jul 2010
- 2Jun 2010
- 6May 2010
- 8Apr 2010
- 7Mar 2010
- 8Feb 2010
- 10Jan 2010
- 6Dec 2009
- 11Nov 2009
- 8Oct 2009
- 14Sep 2009
- 7Aug 2009
- 11Jul 2009
- 5Jun 2009
- 14May 2009
- 21Apr 2009
- 14Mar 2009
- 20Feb 2009
- 14Jan 2009
- 9Dec 2008
- 14Nov 2008
- 9Oct 2008
- 11Sep 2008
- 15Aug 2008
- 9Jul 2008
- 8Jun 2008
- 14May 2008
- 15Apr 2008
- 14Mar 2008
- 19Feb 2008
- 18Jan 2008
- 17Dec 2007
- 16Nov 2007
- 25Oct 2007
- 10Sep 2007
- 27Aug 2007
- 16Jul 2007
- 27Jun 2007
- 31May 2007
- 28Apr 2007
- 12Mar 2007
- 34Feb 2007
- 31Jan 2007
- 29Dec 2006
- 33Nov 2006
- 20Oct 2006
- 35Sep 2006
- 42Aug 2006
- 35Jul 2006
- 31Jun 2006
- 29May 2006
- 23Apr 2006
- 20Mar 2006
- 23Feb 2006
- 43Jan 2006
- 26Dec 2005
- 31Nov 2005
- 31Oct 2005
- 14Sep 2005
- 31Aug 2005
- 24Jul 2005
- 1Jul 2004
You are here: Weblog von Beat Döbeli Honegger
Hört auf mit egoistischem Kollateralschaden-Tagging!
Rant zu einem nervenden Phänomen in sozialen Netzen
Ich gebe es zu, ist warm hier im Büro. Aber das ist nicht der Grund, dass ich mich jetzt für diesen Rant hinsetze, es liegt eher daran, dass ich in der Sommerpause eher Zeit für solche Postings habe.
Worum geht es? Ich ärgere mich darüber, dass vermehrt User in sozialen Netzwerken Postings mit dem Namen anderer User kommentieren, damit diese auf das Posting aufmerksam werden:
Computergeneriertes Symbolbild
(absichtlich exemplarisch lang, damit spürbar wird, wie mühsam das darüberhinwegscrollen ist...)
Warum mich das ärgert? Für mich ist das eine egoistische Form von digitalem Littering. Zwar werden die getaggten User wie gewünscht benachrichtigt, als Kollateralschaden werden aber auch viele andere User informiert (Notification spam) , dass ein Posting kommentiert worden ist und die Kommentarspalte füllt sich mit Beiträgen, die für 99% der User irrelevant sind (Thread-Verschmutzung). Damit wird die eigene Bequemlichkeit an erste Stelle gesetzt und die Verschlechterung des Signal-Noise-Verhältnisses für andere in Kauf genommen.
Just stop it. Postings lassen sich auch per privater Direktnachricht weiterleiten.
Computergeneriertes Symbolbild
(absichtlich exemplarisch lang, damit spürbar wird, wie mühsam das darüberhinwegscrollen ist...)
Was unterdessen bereits mein Büchergestell kann
Leistungsfähigkeit lokaler generativer Machine-Learning-Systeme
Dies ist eher eine Notiz für mich selbst - oder ein Eintrag in meinem eigenen Techniktagebuch. Im April 2026 hatte ich berichtet, dass ich mir einen Mac Mini für Experimente mit lokalen generativen Machine-Learning-Systemen (LGMLS, Biblionetz:w03773) gekauft hatte.
Erstaunlich, was diese Modelle bereits können. Ich habe meinen lokalen Chatbot gefragt:
was sind die vier kränkungen der menscheit (kopernikus, freud, ???, künstliche intelligenz)?
Qualitätslabel für EdTech-Software?
Aus der Serie "Wünschbarkeit impliziert nicht Machbarkeit"
In letzter Zeit häufen sich die Anfragen nach einer Art Qualitätslabel für Software und Plattformen, die für Bildungszwecke verwendet werden. Lehrpersonen, Schulleitungen und Bildungsbehörden auf verschiedenen Stufen sind verständlicherweise überfordert von der Flut an digitalen Angeboten, die versprechen, das Lernen zu verbessern. Da wäre es doch sehr hilfreich, es gäbe ein entsprechendes, einfach verständliches Qualitätslabel und eine Behörde, welche solche Produkte prüft und labelt.

Ich verstehe diesen Wunsch. Ich zweifle jedoch, ob ein solches Qualitätslabel praktisch umsetzbar wäre und es der Schulpraxis tatsächlich helfen würde.
Ich habe diesbezüglich déjà-vus auf zwei Ebenen:
Hier ein erster Entwurf meiner Vorbehalte:
- Ähnliche Wünsche habe habe ich bereits erlebt bei Lernsoftware als sie noch auf CDs verteilt worden ist und beim Aufkommen von Lernapps für Smartphones und Tablets sowie bei der Messung von Anwendungskompetenzen sowohl von Schüler:innen als auch Lehrpersonen.
- Darüber hinaus habe ich auch sonst immer wieder erlebt, dass Menschen davon ausgehen, dass wenn ein Bedürfnis genügend gross ist, es doch auch eine Lösung dafür geben muss (WuenschbarkeitImpliziertNichtMachbarkeit, Februar 2006).
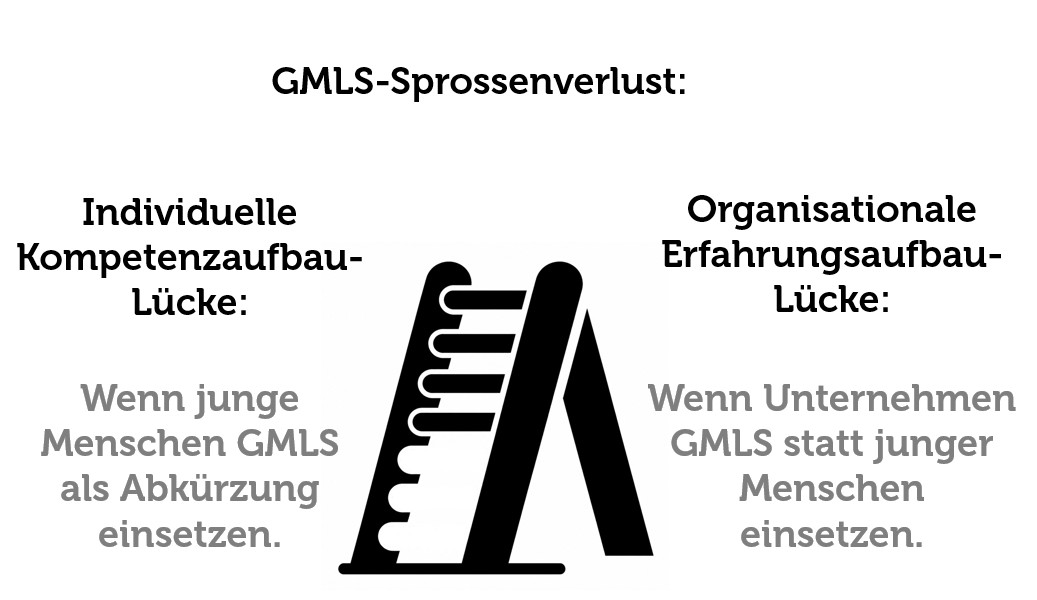
Sprossenverlust
Wie GMLS auf individueller und organisationaler Ebene eine Lücke generieren könnten
Es ist Sommerpause. Zeit um Gedanken und Begriffe zu ordnen. Seit längerem sehe ich Parallelen zwischen zwei möglichen Gefahren von generativen Machine-Learning-Systemen (Biblionetz:w02833). Da ich bisher keine Quelle gefunden habe, welche die beiden Gefahren nebeneinanderstellt und Ähnlichkeiten aufzeigt, habe ich mir kürzlich die Zeit genommen und zuerst alleine und dann mit anderen darüber nachgedacht sowie Begriffe erfunden:
Kühlstrategien empirisch belegen
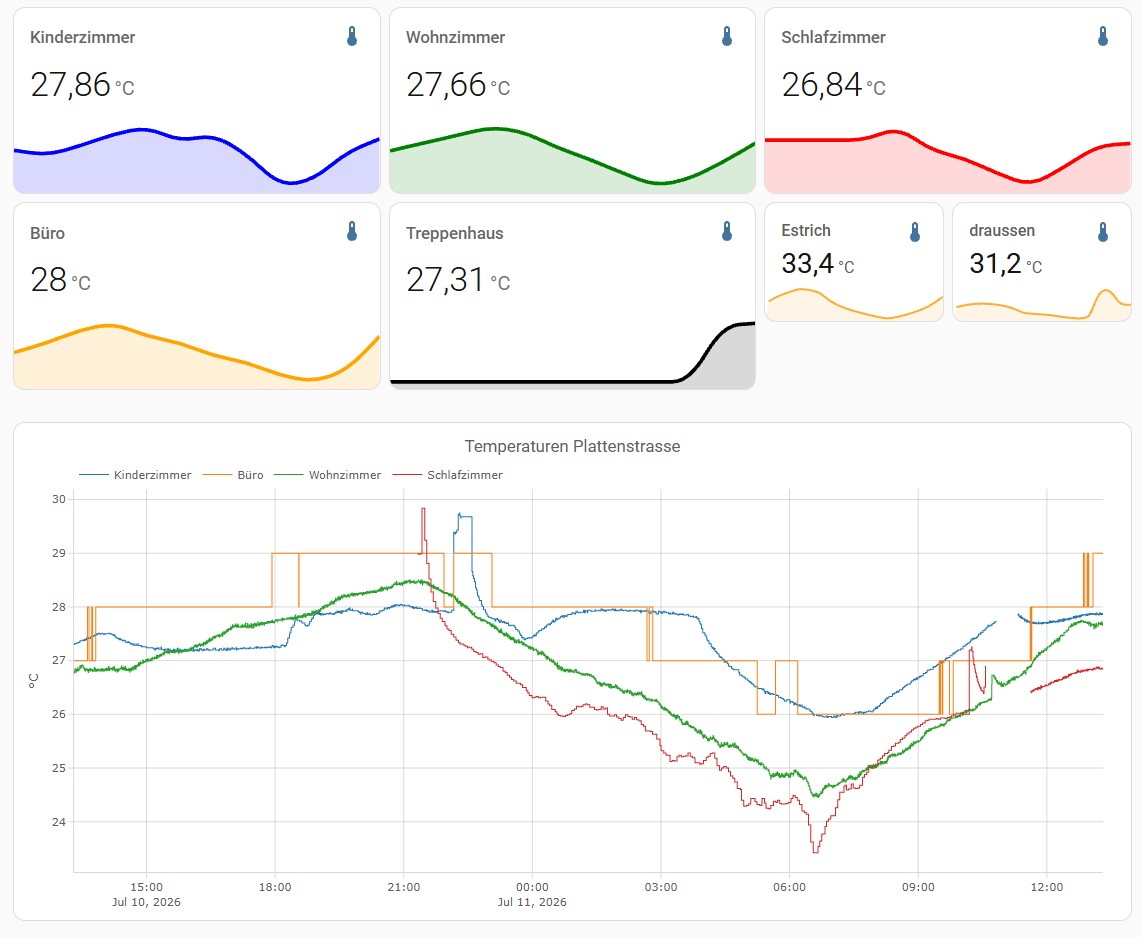
Mit Smarthome-Daten argumentieren
Unser Sohn hat das Pech, einen Wissenschaftler und Smarthome-Nerd als Vater zu haben. Er hätte gerne eine Klimaanlage in seinem Zimmer und ich argumentiere mit Temperaturkurven, welche mir mein Smarthome aufgezeichnet hat.
Kontakt
- Beat Döbeli Honegger
- Plattenstrasse 80
- CH-8032 Zürich
- E-mail: beat@doebe.li
About me
Social Media
This page was cached on 01 Aug 2026 - 21:53.