TOP
TOP categories
TOP Archive
- 3May 2026
- 3Apr 2026
- 3Mar 2026
- 4Feb 2026
- 8Jan 2026
- 7Dec 2025
- 2Nov 2025
- 2Oct 2025
- 2Sep 2025
- 1Aug 2025
- 4Jul 2025
- 1Jun 2025
- 5May 2025
- 5Sep 2024
- 1Aug 2024
- 2Jul 2024
- 1Jan 2024
- 1Dec 2023
- 1Sep 2023
- 2Jul 2023
- 1Jun 2023
- 1Mar 2023
- 1Feb 2023
- 1Jan 2023
- 1Jul 2022
- 1Jan 2022
- 1Oct 2021
- 1Sep 2021
- 1Jun 2021
- 2Apr 2021
- 1Feb 2021
- 1Nov 2020
- 3Sep 2020
- 2Jun 2020
- 1May 2020
- 1Apr 2020
- 2Mar 2020
- 1Feb 2020
- 2Jan 2020
- 1Dec 2019
- 1Nov 2019
- 1Oct 2019
- 4Sep 2019
- 1Jul 2019
- 1Jun 2019
- 3Apr 2019
- 1Mar 2019
- 3Jan 2019
- 1Dec 2018
- 1Nov 2018
- 1Oct 2018
- 1Aug 2018
- 4Jun 2018
- 2Dec 2017
- 3Nov 2017
- 2Oct 2017
- 5Sep 2017
- 4Jul 2017
- 1Jun 2017
- 1Apr 2017
- 1Jan 2017
- 3Dec 2016
- 3Nov 2016
- 1Oct 2016
- 3Sep 2016
- 1Aug 2016
- 1Jun 2016
- 3May 2016
- 4Apr 2016
- 3Mar 2016
- 4Jan 2016
- 3Dec 2015
- 3Nov 2015
- 2Oct 2015
- 3Sep 2015
- 4Aug 2015
- 3Jul 2015
- 5Jun 2015
- 8May 2015
- 5Apr 2015
- 6Mar 2015
- 5Feb 2015
- 6Jan 2015
- 6Dec 2014
- 10Nov 2014
- 5Oct 2014
- 9Sep 2014
- 3Aug 2014
- 3Jul 2014
- 6Jun 2014
- 4May 2014
- 8Apr 2014
- 6Mar 2014
- 5Feb 2014
- 4Jan 2014
- 6Dec 2013
- 7Nov 2013
- 15Oct 2013
- 4Sep 2013
- 8Aug 2013
- 7Jul 2013
- 13Jun 2013
- 5May 2013
- 5Apr 2013
- 8Mar 2013
- 4Feb 2013
- 10Jan 2013
- 9Dec 2012
- 7Nov 2012
- 10Oct 2012
- 7Sep 2012
- 8Aug 2012
- 7Jul 2012
- 4Jun 2012
- 3May 2012
- 9Apr 2012
- 9Mar 2012
- 1Feb 2012
- 6Jan 2012
- 9Dec 2011
- 3Nov 2011
- 10Oct 2011
- 13Sep 2011
- 4Aug 2011
- 8Jul 2011
- 7Jun 2011
- 8May 2011
- 7Apr 2011
- 4Mar 2011
- 3Feb 2011
- 7Jan 2011
- 7Dec 2010
- 10Nov 2010
- 11Oct 2010
- 9Sep 2010
- 6Aug 2010
- 6Jul 2010
- 2Jun 2010
- 6May 2010
- 8Apr 2010
- 7Mar 2010
- 8Feb 2010
- 10Jan 2010
- 6Dec 2009
- 11Nov 2009
- 8Oct 2009
- 14Sep 2009
- 7Aug 2009
- 11Jul 2009
- 5Jun 2009
- 14May 2009
- 21Apr 2009
- 14Mar 2009
- 20Feb 2009
- 14Jan 2009
- 9Dec 2008
- 14Nov 2008
- 9Oct 2008
- 11Sep 2008
- 15Aug 2008
- 9Jul 2008
- 8Jun 2008
- 14May 2008
- 15Apr 2008
- 14Mar 2008
- 19Feb 2008
- 18Jan 2008
- 17Dec 2007
- 16Nov 2007
- 25Oct 2007
- 10Sep 2007
- 27Aug 2007
- 16Jul 2007
- 27Jun 2007
- 31May 2007
- 28Apr 2007
- 12Mar 2007
- 34Feb 2007
- 31Jan 2007
- 29Dec 2006
- 33Nov 2006
- 20Oct 2006
- 35Sep 2006
- 42Aug 2006
- 35Jul 2006
- 31Jun 2006
- 29May 2006
- 23Apr 2006
- 20Mar 2006
- 23Feb 2006
- 43Jan 2006
- 26Dec 2005
- 31Nov 2005
- 31Oct 2005
- 14Sep 2005
- 31Aug 2005
- 24Jul 2005
- 1Jul 2004
...wenn auch vermutlich nur kurz  Mein Ego-Google-Alert hat mich heute darauf aufmerksam gemacht, dass es seit dem 23. April 2006 einen kleinen Artikel in der deutschen Wikipedia zum Biblionetz gibt:
Mein Ego-Google-Alert hat mich heute darauf aufmerksam gemacht, dass es seit dem 23. April 2006 einen kleinen Artikel in der deutschen Wikipedia zum Biblionetz gibt:
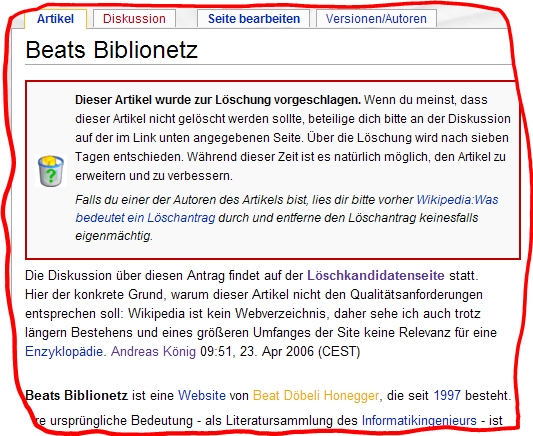
Am gleichen Tag, an dem der Artikel entstand, wurde er auch bereits wieder zur Löschung vorgeschlagen. Und wie das bei der Wikipedia so läuft, wird da nicht einfach gelöscht, sondern zuerst über die Löschung diskutiert:
http://de.wikipedia.org/wiki/Wikipedia:L%C3%B6schkandidaten/23._April_2006#Beats_Biblionetz
Ich habe mich beim Lesen der bisherigen Diskussion, die nta bene um ein Vielfaches grösser ist als der entsprechende Artikel, köstlich amüsiert. Die hitzige Debatte beginnt schon wunderbar:
Gefallen hat mir auch
Mein Ego-Google-Alert hat mich heute darauf aufmerksam gemacht, dass es seit dem 23. April 2006 einen kleinen Artikel in der deutschen Wikipedia zum Biblionetz gibt:
http://de.wikipedia.org/wiki/Beats_BiblionetzDoch das junge Pfänzchen ist (zu Recht?) bereits vom Aussterben bedroht:
- Wikipedia ist kein Webverzeichnis, daher sehe ich auch trotz längern Bestehens und eines größeren Umfanges der Site keine Relevanz für eine Enzyklopädie. Andreas König 09:52, 23. Apr 2006 (CEST)
- Na, dann stell ich jetzt mal mit Deiner Begründung einen Löschantrag für Wikipedia! Du Witzbold! dontworry 10:50, 23. Apr 2006 (CEST)
Beats Biblionetz kann wunderbar für sich selbst sprechen, da braucht es keinen Wikipedia-Artikel. Löschen und wieder einstellen, wenn es z. B. von Google aufgekauft wurde oder irgend etwas anderes Großes damit passiert ist. --TM 02:13, 25. Apr 2006 (CEST)
Aber Google wird das Biblionetz nie aufkaufen, denn
Und immernoch ist diese Website eine rein subjektive Wiedergabe von gefilterten Inhalten der gelesenen Büchern des Herrn Honegger von fragwürdiger Relevanz für die Allgemeinheit. ReqEngineer Au weia!!! 23:41, 25. Apr 2006 (CEST)
Macht weiter so, ich lese das gerne
ClockR
22 April 2006
| Beat Döbeli Honegger
Via Namics Blog bin ich auf eine hübsche Variante gestossen, wie man die Zeit anzeigen kann:

Zu finden unter http://www.quasimondo.com/clockr.php, wo es auch einen entsprechenden Screensaver für Windows zum Downloaden gibt.
Praktisch vor einem Jahr habe ich die digitale Bilderuhr entdeckt, die aber noch zum Downloaden als Programm gedacht war. Nun, The Web is the computer! darum gibt's das ganze als Mashup unter Ausnutzung des Flickr-API. Cool.
Semacode
20 April 2006
| Beat Döbeli Honegger
Martin Hofmann hat mich mit seinem interessanten Projekt Tagging the Historical Rorschach (cool!) auf das Projekt Semacode aufmerksam gemacht.
Ein frei verfügbarer Algorithmus codiert dabei URLs in zweidimensionale Barcodes:

Diese können von elektronischen Geräte mit Kameras (Mobiltelefon, Handheld, Notebook usw.) erfasst und mit einer kostenlosen Software decodiert werden. Mittels Internetverbindung (wie auch immer) kann danach die URL abgerufen werden. Damit ist eine Verbindung zwischen physischer Welt und virtueller Welt möglich. Anders formuliert: Fotografiere einen Semacode in der physischen Welt und Du landest auf der passenden Webseite in der virtuellen Welt.
Die Idee hinter Semacode ist nicht sehr neu, mein letzter Subnotebook von Sony, der Vaio Picturebook C1VE hatte eine eingebaute Webcam und ein Programm, mit dem Cybercode (Biblionetz:w01163) genannte Barcodes gedruckt und mit der Webcam auch wieder erkannt werden konnten:

Das aus dem Jahr 2000 stammende Forschungspaper von Sony (Biblionetz:t05729) enthält einige recht futuristisch anmutende Anwendungsmöglichkeiten (z.B. "zeige Deinem Computer ein Papierdokument mit Cybercode, er wird die elektronische Variante davon auf dem Bildschirm anzeigen").
Ich hatte vor etwa drei Jahren angefangen, meine Bücher mit Cybercodes auszustatten und mein Computer öffnete daraufhin die richtige Seite des Biblionetzes, wenn ich das Buch vor den Computer hielt. Doch Cybercode setzte sich nicht durch, Sony begrub das Projekt. Jetzt scheinen mit der zunehmenden Verbreitung von Fotohandys mit Java und Internetverbindungsmöglichkeit die Voraussetzungen für einen Durchbruch dieser Technologie geschaffen zu sein.
Was mir sofort einfällt:
- Bisher gibt's scheinbar kein Programm für PCs, die gleich den ganzen Erfassungs- und URL-Öffnungsprozess übernehmen, sondern erst ein Javaprogramm, das ein File als Input nimmt und eine URL als Output liefert.
- Biblionetz: Muss ich jetzt meine Bücher ver-semacoden?
- Ich sollte gleich eine TWiki-Variable implementieren
%SEMACODE%, die den Semacode der aktuellen TWiki-Seite ausgibt
- Philipp Schaufelberger meint: Bookcrossing + semacode = Einfacheres und lustigeres Bookcrossing
Wo sitzen meine Leser/innen? Ha! Wenig erstaunlich, im deutschsprachigen Raum:
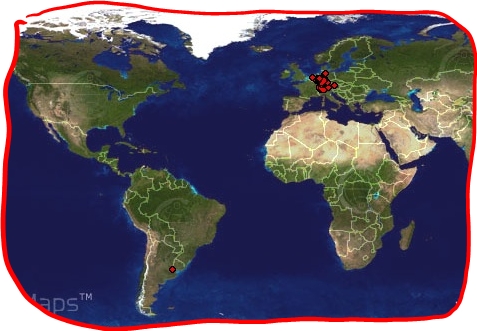
Diese Erkenntnis bietet mir seit einigen Tagen der Dienst http://www.clustrmaps.com, der die verfügbaren geographischen Angaben zu den IP-Adressen meiner Weblog-Besucher/innen auswertet und auf einer täglich aktualisierten Weltkarte aufzeichnet.
Ich würd's ja gerne mit dem Biblionetz ausprobieren, aber dessen Traffic ist zu gross für die kostenlose Version von ClustrMaps.
,
Heute morgen habe ich folgende Nachricht auf meinem Computer gefunden:
Find ich ehrlich gesagt etwas problematisch ein Wiki Blog zu nennen, nur weil die Einträge chronologisch sortiert sind. Wie steht es denn mit Funktionen wie Trackback? Oder ist das alles absichtlich so abgeriegelt?
Hört, hört!
Definitionen sind immer spannend. Zum konkreten Begriff: Unter Biblionetz:w01272 habe ich über 10 Definitionen des Begriffs Weblog gesammelt. Trackback kommt in keiner einzigen als notwendiges Kriterium vor. Mein "Weblog" entspricht in etwa den gesammelten Definitionen von Weblog: Es ist umgekehrt chronologisch geordnet, arbeitet mit Permalinks und verfügt über Kategorien, RSS-Feeds und die Möglichkeit von Kommentaren durch BesucherInnen (dazu später...).
Definitionen sind eine gefährliche Sache bei all den neuen Webdiensten, um die sich eine Community gebildet hat. So war ich etwas erstaunt, an der WikiSym von mehreren Teilnehmenden zu hören, ein Wiki mit WYSIWYG-Funktion sei kein Wiki mehr. Das Editieren mit kryptischen Markups scheint für die alteingesessenen Wikianer konstituierend für ein Wiki.
Was mich aber noch mehr erstaunt hat an dieser Mitteilung heute morgen: Zum ersten Mal höre ich den Vorwurf, mein Wiki sei abgeriegelt. Gibt's etwas offeneres als (m)ein Wiki? Nach einer kurzen Registration unter TWiki.TWikiRegistration (manche würden das als Captcha (Biblionetz:w01616) bezeichnen) kann man in meinem "Weblog" nicht nur Kommentare anbringen, sondern auch die Weblogeinträge selbst verändern.
So wie sich früher das Schnabeltier als eierlegendes Säugetier die Systematiker zur Verzweiflung gebracht hat, geschieht dies heute mit digitaler Hard- und Software, die sich dank allgegenwärtiger Konvergenz (heisst im Web 2.0: Mash-up) Systematisierungsversuchen zu widersetzen versucht.
Kommentare willkommen
- Habe ich da nicht mal in Beats Weblog gelesen, dass Wiki-Schreiber sozial und Blog-Schreiber egoistisch sind? Ich empfehle den definitorischen Wikianern und Bloggern mal den Artikel zu Ambiguitätstoleranz zu lesen. - MD
- - BD
-
- @MD ist Beat dann ein Blog- oder Wikischreiber? - RA
- @Beat: Hier mein Handmade Trackback: http://www.loveitorchangeit.com/2006/04/17/grenze-zwischen-wiki-und-weblog
- Und noch ein manuelles Trackback: http://hodel-histnet.blogspot.com/2006/04/aus-der-welt-der-blogs-und-wikis-was.html - BD
- Spamschutz: Sehe ich das eigentlich richtig, dass meine Mailadresse hier von jedem Robot aus der Userliste kopiert werden kann? → Muss man selbst bearbeiten. Per default wird die Adresse einfach angezeigt. Gar nicht schön!
- Mailadressen werden in diesem Wiki nicht einfach angezeigt, sie haben einen (zugegebenermassen geringen) Spamschutz: Das @-Zeichen wird als
@codiert gesendet. Ein Roboter muss also nach@suchen. Wenn ein Roboter das kann, dann kann er auch nachdotundpunktusw. suchen.
- Mailadressen werden in diesem Wiki nicht einfach angezeigt, sie haben einen (zugegebenermassen geringen) Spamschutz: Das @-Zeichen wird als
- Wer hat eigentlich meine Skype Nachricht ausgedruckt und auf den Computer gelegt ;-)? - RA
Kontakt
- Beat Döbeli Honegger
- Plattenstrasse 80
- CH-8032 Zürich
- E-mail: beat@doebe.li
About me
Social Media
This page was cached on 27 May 2026 - 10:24.