Biblionetz
Postings zum Biblionetz
Biblionetz Archive
- 1Dec 2025
- 1Jul 2024
- 1Feb 2023
- 1Oct 2019
- 1Apr 2019
- 1Mar 2019
- 1Sep 2017
- 1Jan 2016
- 1Nov 2014
- 1May 2014
- 1Apr 2014
- 1Apr 2013
- 1Mar 2013
- 1Feb 2013
- 1Jan 2013
- 1Dec 2012
- 1Oct 2012
- 1Jul 2012
- 1Apr 2012
- 1Jun 2011
- 2May 2011
- 2Apr 2011
- 2Nov 2010
- 2Sep 2010
- 2Jul 2010
- 1Mar 2010
- 1Feb 2010
- 3Jan 2010
- 2Nov 2009
- 1Aug 2009
- 1Jul 2009
- 2May 2009
- 2Apr 2009
- 1Mar 2009
- 2Feb 2009
- 1Jan 2009
- 2Dec 2008
- 1Oct 2008
- 1Sep 2008
- 6Aug 2008
- 1Jun 2008
- 2Apr 2008
- 1Feb 2008
- 1Jan 2008
- 3Dec 2007
- 1Nov 2007
- 1Oct 2007
- 1Aug 2007
- 2Jul 2007
- 2May 2007
- 3Apr 2007
- 1Mar 2007
- 4Jan 2007
- 5Dec 2006
- 3Oct 2006
- 2Sep 2006
- 2Aug 2006
- 3Jul 2006
- 2Jun 2006
- 4May 2006
- 3Apr 2006
- 1Feb 2006
- 5Jan 2006
- 3Nov 2005
- 1Oct 2005
- 5Aug 2005
- 1Jul 2005
- 1Jul 2004
Biblionetz
Postings zum Biblionetz
The Myth of the Paperless Office (Biblionetz:b01255) ist eines der Bücher, die mir Marc Pilloud (Biblionetz:p00336) heute geschenkt hat, weil er auf 90% seiner Bücher in Papierform verzichten will. Marc macht Ernst mit dem Paperless Office und freut sich auf den zurückgewonnenen Platz in der Wohnung. Viele Bücher hat Marc digital, bei anderen geht er davon aus, dass sie eh nur nutzlos im Büchergestell gestanden haben und er sie nicht mehr aktiv nutzen würde.

Ich bewundere Marc für seine konsequente Haltung: Loslassen können und darauf vertrauen, dass das Wesentliche schon zur Verfügung steht, wenn es gebraucht wird. Ich kann nicht verleugnen, dass der physische oder digitale Besitz von Content mir eine (trügerische) Sicherheit vermittelt, ich hätte den Content eher zur Verfügung. Das hat ja auch etwas: Ich stehe vor meinem Büchergestell und lasse den Blick über die geordneten Bücher schweifen, was mir beim Nachdenken und Erarbeiten von Neuem schon öfters neue Ideen oder Perspektiven gebracht hat.

So ist es auch nicht verwunderlich, dass ich Marcs konsequente Haltung begrüsse: Schliesslich enthält jetzt mein Büchergestell einige spannende Werke mehr, so dass mir nur noch die Zeit fehlt, sie auch zu lesen  Ich finde es spannend, dass wir uns beide mit den Auswirkungen der Digitalisierung auf die Bildung beschäftigen, eine gemeinsame (ETH-)Ausbildung genossen haben, oft ähnlich arbeiten, in der Buchfrage aber unterschiedliche Präferenzen haben. Das erinnert mich an die Überlegungen, wie gross die verfügbare Bildschirmfläche idealerweise sein sollte. Auch dort schwanken die Antworten zwischen Smartphone-Screen und 2 x 24 Zoll...
Und sollte Marc merken, dass er die physischen Bücher doch vermisst: Sie stehen bei mir im Gestell, ich betrachte sie als Dauerleihgabe
Ich finde es spannend, dass wir uns beide mit den Auswirkungen der Digitalisierung auf die Bildung beschäftigen, eine gemeinsame (ETH-)Ausbildung genossen haben, oft ähnlich arbeiten, in der Buchfrage aber unterschiedliche Präferenzen haben. Das erinnert mich an die Überlegungen, wie gross die verfügbare Bildschirmfläche idealerweise sein sollte. Auch dort schwanken die Antworten zwischen Smartphone-Screen und 2 x 24 Zoll...
Und sollte Marc merken, dass er die physischen Bücher doch vermisst: Sie stehen bei mir im Gestell, ich betrachte sie als Dauerleihgabe  Konkret sind es übrigens die folgenden Bücher:
Biblionetz:b01255 The Myth of the Paperless Office
Konkret sind es übrigens die folgenden Bücher:
Biblionetz:b01255 The Myth of the Paperless Office
Donald A. Norman (Biblionetz:p00289)
Ich finde es spannend, dass wir uns beide mit den Auswirkungen der Digitalisierung auf die Bildung beschäftigen, eine gemeinsame (ETH-)Ausbildung genossen haben, oft ähnlich arbeiten, in der Buchfrage aber unterschiedliche Präferenzen haben. Das erinnert mich an die Überlegungen, wie gross die verfügbare Bildschirmfläche idealerweise sein sollte. Auch dort schwanken die Antworten zwischen Smartphone-Screen und 2 x 24 Zoll...
Und sollte Marc merken, dass er die physischen Bücher doch vermisst: Sie stehen bei mir im Gestell, ich betrachte sie als Dauerleihgabe
Konkret sind es übrigens die folgenden Bücher:
Biblionetz:b01255 The Myth of the Paperless Office Donald A. Norman (Biblionetz:p00289)
- Biblionetz:b00204 The Psychology of Everyday Things
- Biblionetz:b01622 Emotional Design
- Biblionetz:b00325 The Invisible Computer
- Biblionetz:b00751 Ins Universum der technischen Bilder
- Biblionetz:b05066 Medienkultur
- Biblionetz:b00291 Kommunikologie
- Biblionetz:b03124 Maeda @ Media
- Biblionetz:b03123 Creative Code
%STARTBLOG% slideshare ist das Youtube der Folien. Scheinbar alle stellen ihre Folien nach oder bereits vor der Präsentation auf Slideshare zur Verfügung und erhalten dafür im Gegenzug detaillierte Statistiken, wann ihre Folien wie oft angeshcaut worden sind.
Bereits seit längerem denke ich drüber nach, ob ich meine Folien ebenfalls auf Slideshare hochladen sollte. Nicht wenige berichten ja vom Effekt, dass die Views auf Slideshare massiv höher ausfallen als die jeweilige Zuhörerschaft vor Ort beim realen Vortrag.
Es gibt jedoch drei Gründe, warum ich mich weiterhin dagegen entscheide:
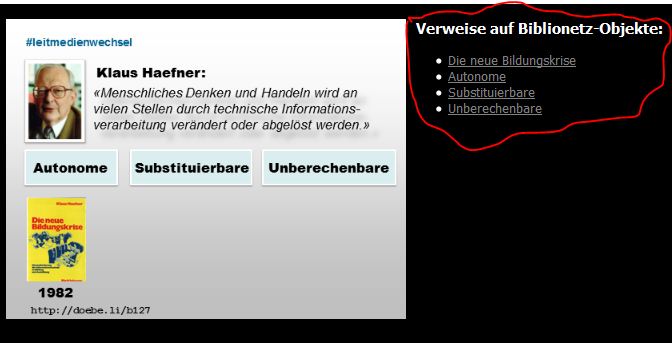
Verweise auf Biblionetzobjekte bei Folien
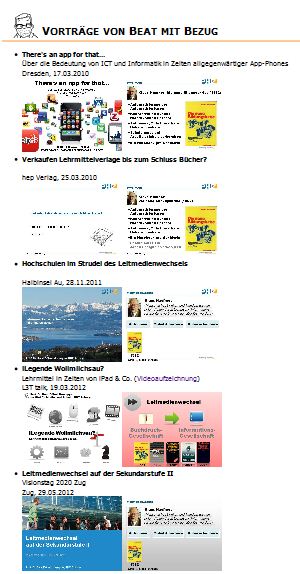
Verweise auf Vortragsfolien im Biblionetz
Was dadurch natürlich unerbittlich sichtbar wird, ist mein zunehmendes Folien-Recycling : Ich werde dummerweise öfters für Vorträge angefragt als ich etwas neues zu erzählen habe, so dass ich gezwungenermassen anfange, neue Vorträge aus bestehenden Vorträgen nach Zeitbudget und Zielpublikum zusammenzustellen (etwas, dass ich frühere immer gehasst habe...).
Ein kleiner Blick hinter die Kulissen: Die Bezüge zwischen Folien und Biblionetz-Objekten muss ich in meiner Datenbank von Hand herstellen (wie sonst?). Mühsam war aber bisher, dass ich diese Bezüge erneut herstellen musste, wenn ich eine Folie in einem anderen Vortrag erneut verwendet habe. Die sechsstünde Bahnfahrt von Zürich nach Hagen vom vergangenen Sonntag hat mir nun die notwendige Ruhe am Stück verschafft, um dieses Problem wegzuprogrammieren. Meine Datenbank (MS-Access) kann nun die Notizenfelder der Präsentationssoftware (MS Powerpoint) auslesen und verändern. Damit kann ich alle Biblionetz-Metadaten ins Notizfeld einer Folie schreiben. Wenn ich nun diese Folie per copy&paste in eine neue Präsention einfüge, werden diese Metadaten mitkopiert und können nach Fertigstellung der Präsentation auf Knopfdruck ins Biblionetz eingelesen werden. Das Wiederverwerten von Folien ist somit mit weniger Aufwand verbunden. (Keine Sorge, ich werde trotzdem weiterhin neue Folien generieren
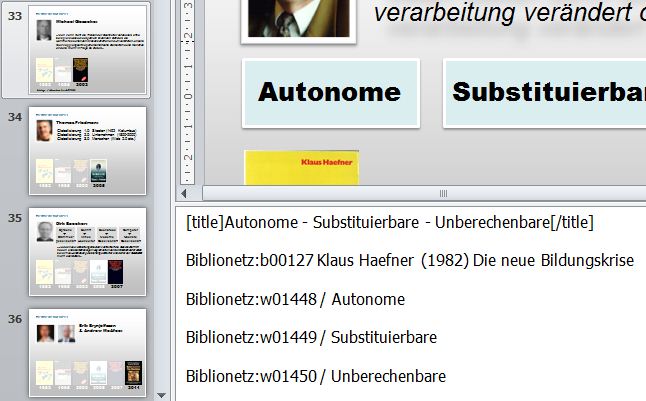
Biblionetz-Metadaten im Notizfeld der Folie
Hier zwei Ausschnitte aus dem Code, wie man mit VBA aus Access auf die Notizen in einer Powerpoint-Präsentation zugreifen kann:
Worauf warten diese Follower?
Auf Deine Abschlussfrage kann ich Dir eine (Teil-)Erklärung geben, Beat: Ich wurde automatisch Dein Slideshare-Follower, da ich mich auf Slideshare mit meinem Facebook-Account eingeloggt habe und wir im Gesichterbuch befreundet sind. Gruss, Ruedi -- Main.RuediArnold - 18 Oct 2012 OK, das erklärt einiges. -- Main.BeatDoebeli - 18 Oct 2012 ,
- 1. Hoheit über meine Daten
Auch wenn ich die meisten meiner Arbeitsergebnisse kostenlos veröffentliche will ich trotzdem eine gewisse Kontrolle darüber behalten. Ich will entscheiden können, wo, wann und wie lange welche Produkte von mir im Netz zu finden sind. So kann ich auch bestimmen, in welchem Kontext meine Produkte zu sehen sind. Konkret bedeutet das z.B., dass ich keine Werbung neben meinen Folien haben will.
Zugegeben, mir als Informatiker fällt es leichter, mir meine eigene Infrastruktur aufzubauen, aber mir scheint es wäre allgemein keine schlechte Idee, wenn man die eigene digitale Identität nicht auf fremden kommerziellen Dienstleistern aufbauen würde (siehe dazu Sascha Lobo: Euer Internet ist nur geborgt (Biblionetz:t14297)).
- 2. slideshare-usability
Für mich unverständlicherweise werden bei mir in zahlreichen Firefox-Versionen keine Navigationsknöpfe angezeigt, sprich ich komme bei einer Präsentation nie über Folie eins raus. Im Netz findet man dazu einige Problembeschreibungen, erstaunlicherweise nicht aber im Supportbereich von slideshare selbst. Will ich meine Folien wirklich an einem Ort präsentieren, der mit einem weitverbreiteten Browser nicht navigierbar ist? (Ja, evtl. könnte ich das Problem für meinen Browser lösen, aber wie vielen anderen mit Firefox ist der Zugang verwehrt?)
Das schwerwiegendere Usability-Problem aus meiner Sicht ist die fehlende Möglichkeit von slideshare, einzelne Folien einer Präsentation mittels einer URL zu referenzieren. Ich möchte in Tweets/Blogposts/etc. auf Folie 57 der Präsentation abcde verweisen können. Meines Wissens bietet slideshare diese Möglichkeit bisher nicht.
- 3. Biblionetz-Integration
Der dritte Grund ist nicht sehr übertragbar: Zu meinen Denk- und Arbeitswerkzeugen gehört das Biblionetz. Nur wenn ich die Folien selbst publiziere, habe ich die Möglichkeit, zwischen Biblionetz und Folien gegenseitige Bezüge, sprich Links zu setzen. Konkret wird bei vielen Folien von mir auf entsprechende Biblionetzobjekte (Bücher, Begriff, Aussagen etc.) verwiesen und umgekehrt ist im Biblionetz sichtbar, auf welchen meiner Folien das entsprechende Objekt auftaucht.
Verweise auf Biblionetzobjekte bei Folien
Verweise auf Vortragsfolien im Biblionetz
Biblionetz-Metadaten im Notizfeld der Folie
Set pp = New PowerPoint.Application
Set praesi = pp.Presentations.Open(c_PRESENTATIONS & speicherort, , , msoFalse)
[...]
If praesi.Slides(folienNummer).NotesPage.Shapes.Placeholders(2).TextFrame.hastext Then
foliennotizen = praesi.Slides(folienNummer).NotesPage.Shapes.Placeholders(2).TextFrame.TextRange
Damit wären aus meiner Sicht alle Fragen zu slideshare beantwortet. Ausser einer: Warum habe ich Follower auf slideshare, auch wenn ich dort noch nie was publiziert habe?
Worauf warten diese Follower?
Auf Deine Abschlussfrage kann ich Dir eine (Teil-)Erklärung geben, Beat: Ich wurde automatisch Dein Slideshare-Follower, da ich mich auf Slideshare mit meinem Facebook-Account eingeloggt habe und wir im Gesichterbuch befreundet sind. Gruss, Ruedi -- Main.RuediArnold - 18 Oct 2012 OK, das erklärt einiges. -- Main.BeatDoebeli - 18 Oct 2012 ,
Derzeit nehmen die Versuche zu, mich im digitalen Raum erziehen zu wollen, bzw. mir die Netiquette nahezubringen. So werde ich nicht nur als arroganter Twitterer, sondern auch als unfeinfühliger-SEO-Outer bezeichnet. Das kommt so:
Das Biblionetz ist aufgrund seiner zahlreichen und stabilen (15 Jahre...) URLs teilweise gut gerankt in Suchmaschinen. Das zieht das Interesse von Suchmaschinenoptimierern an, und so erhalte ich regelmässig und immer häufiger Anfragen bezüglich Linktausch. Teilweise wären die Themen sogar passend, meistens kann ich aber keinen Zusammenhang zum Biblionetz erkennen. Einen solchen Fall habe ich vor ca. einem Jahr auf Google+ gepostet:
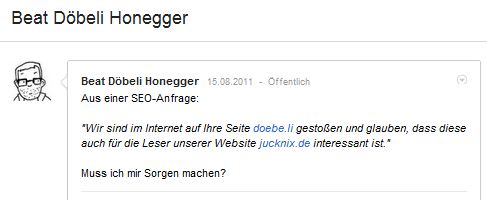
Fast ein Jahr später werde ich nun drauf aufmerksam gemacht, dass das nicht sehr feinfühlig sei, eine solche Anfrage öffentlich zu machen:

Was daran schlimm ist? Schlimm ist es nicht, nur nervend, dass ich dauernd SEO-Anfragen erhalte und mich wundere, welche Webangebote etwas mit dem Biblionetz zu tun haben sollten. Die Masse der Anfragen führt dazu, dass ich solche E-Mails als Spam empfinde und auch entsprechend markiere.
Umgekehrt gefragt: Was ist daran schlimm, dass ich diese Anfrage veröffentliche?
Ich fühle mit. Bitte im Arroganz-Modus bleiben! Gruß, JR -- Main.JochenRobes - 03 Jul 2012
- Ist es ja das Ziel der SEO-Aktivitäten, dass die beworbenen Links veröffentlicht und verbreitet werden. Das tu ich ja
- WEnn ja alle SEO so arbeiten, dann ist dieses Verfahren auch kein Geheimnis, das ich für mich behalten müsste.
Ich fühle mit. Bitte im Arroganz-Modus bleiben! Gruß, JR -- Main.JochenRobes - 03 Jul 2012
 Manchmal macht Informatiker sein Spass: Damit ich bei Büchern und ausgedruckten Artikeln (ja, das gibt es auch bei mir) rasch das entsprechende Biblionetz-Objekt finde, schreibe ich seit langem die entsprechende Biblionetz-ID ins Buch oder auf den Text. Doch irgendwie müsste das heute doch auch anders gehen...
Stimmt. Mit einer halben Stunde Installieren und den gelieferten Beispielcode anpassen druckt nun meine Biblionetz-Datenbank eine entsprechende Etikette mit QR-Code, einem 2D-Barcode (Biblionetz:w02048) welche direkt auf die passende Biblionetz-Seite verlinkt.
Manchmal macht Informatiker sein Spass: Damit ich bei Büchern und ausgedruckten Artikeln (ja, das gibt es auch bei mir) rasch das entsprechende Biblionetz-Objekt finde, schreibe ich seit langem die entsprechende Biblionetz-ID ins Buch oder auf den Text. Doch irgendwie müsste das heute doch auch anders gehen...
Stimmt. Mit einer halben Stunde Installieren und den gelieferten Beispielcode anpassen druckt nun meine Biblionetz-Datenbank eine entsprechende Etikette mit QR-Code, einem 2D-Barcode (Biblionetz:w02048) welche direkt auf die passende Biblionetz-Seite verlinkt.

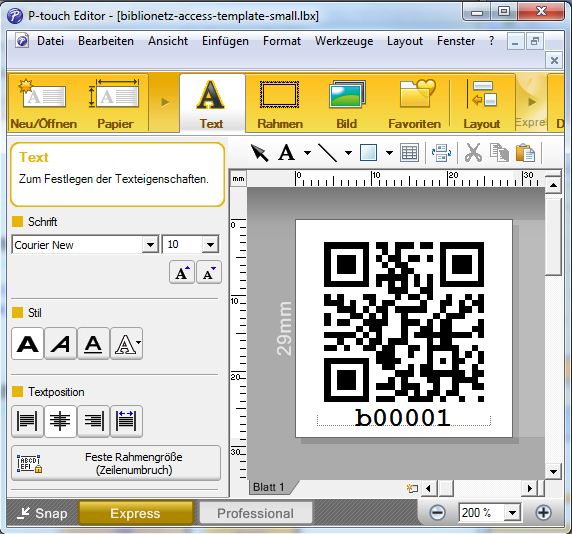
Public Sub QR_label(inhalt As String)
Dim ObjDoc As bpac.Document
Dim strFilePath As String
Set ObjDoc = CreateObject("bpac.Document")
strFilePath = strEtikettenPfad & "biblionetz-access-template-small.lbx"
If (ObjDoc.Open(strFilePath) <> False) Then
' Text
ObjDoc.GetObject("Textfeld").Text = inhalt
ObjDoc.GetObject("Barcode").Text = "http://doebe.li/" & inhalt
ObjDoc.StartPrint "", bpoDefault
ObjDoc.PrintOut 1, bpoDefault
ObjDoc.EndPrint
ObjDoc.Close
End If
Set ObjDoc = Nothing
End Sub
Das Dokumentieren hier im Blog hat nun nochmals fast 30 Minuten gedauert...
,
Die Suchmaschinenanbieter (Biblionetz:w00718) Bing (Microsoft), Google, Yahoo! und sitemaps.org haben sich zusammengesetzt und mit http://schema.org Vorschläge zur semantischen Kennzeichnung von Daten in Webseiten erarbeitet. Dank diesen Markups sollte dann eine Suchmaschine wissen, dass hier Daten über eine Person, ein Ereignis, ein Produkt etc. zu finden sind.
http://schema.org ist beileibe nicht der erste Versuch, ein semantisches Web (Biblionetz:w01364) zu bilden. Interessant an diesem Vorschlag scheint mir, dass er von den grossen Suchmaschinenbetreibern initiiert worden ist und relativ einfach zu implementieren ist. Dieser fast schon bottom-up-Upsatz ist vielleicht Erfolg versprechender als die top-down-Versuche mit 100% definierten Strukturen. Gleichzeitig könnte dies aber auch die Schwäche von schema.org sein, mindestens derzeit sind die Objekte relativ schwammig definiert.
Ich habe jedenfalls Bei Personen, Büchern und Texten im Biblionetz die entsprechenden Ergänzungen im Biblionetz eingebaut, so dass in den nächsten 6 Monaten alle Biblionetzseiten entsprechend ausgezeichnet sein werden.
Was wird jetzt passieren? Suchmaschinen werden die Inhalte des Biblionetzes besser einordnen können. Das kann entweder dazu führen, dass das Biblionetz bei entsprechenden Suchanfragen besser gefunden und dargestellt wird oder es kann dazu führen - wie andernorts bereits befürchtet wird - dass Surfende gar nicht mehr auf die Originalseiten gehen (müssen), um zur gesuchten Information zu kommen. Diese Befürchtungen - einhergehend mit sinkenden Werbeeinnahmen - hegen Zeitungsverlage (Biblionetz:w02193) ja schon länger im traditionellen, nicht-semantischen Web...
Technisches P.S.: Google bietet mit dem Rich Snippets Testing Tool eine Möglichkeit zu prüfen, welche semantischen Daten aus einer Webseite auslesbar sind. (Warum der Google search preview sich beim Biblionetz noch immer beklagt, er habe nicht genügend Daten, ist mir noch nicht klar. Das da scheinen mir doch schon recht viele semantische Daten zu sein... ist dank Andrea Cantieni geklärt:
"[ ] rich snippets previews are not yet shown for schema.org markup. Well be adding this functionality soon." ( http://bit.ly/lP2aDa ) Oder alternativ "data-vocabulary.org/Person". Dann gibt es ein Preview, wenn z.B. die itemprops "name", "role" und "affiliation" vorkommen -- Main.AndreaCantieni - 17 Jun 2011
"[ ] rich snippets previews are not yet shown for schema.org markup. Well be adding this functionality soon." ( http://bit.ly/lP2aDa ) Oder alternativ "data-vocabulary.org/Person". Dann gibt es ein Preview, wenn z.B. die itemprops "name", "role" und "affiliation" vorkommen -- Main.AndreaCantieni - 17 Jun 2011
Kontakt
- Beat Döbeli Honegger
- Plattenstrasse 80
- CH-8032 Zürich
- E-mail: beat@doebe.li
About me
Social Media
This page was cached on 19 Apr 2026 - 03:49.