Nachdem ich dieses Jahr verschiedentlich
aus dem Alltag als Biblionetzkar berichtet habe, hier ein Einblick ins Biblionetzkarleben während der Weihnachtsfeiertage.
Diese Schilderung ist vor allem für Nichtinformatiker/innen gedacht, da ich in letzter Zeit öfters die Meinung gehört habe, dass im Biblionetz wohl alles automatisch geschähe, ansonsten ein solcher Umfang nicht durch eine Einzelperson leistbar sei.
Wie sich Nichtinformatiker/innen das Leben der Informatiker vorstellen...
(Ich bin mir aber bewusst, dass Nichtinformatiker/innen wohl spätestens beim zweiten Abschnitt gelangweilt weiterklicken und echte Informatiker/innen sich über meine stümperhaften Basteleien belustigen werden.)
Seit unterdessen elf Jahren (ja, das Biblionetz feiert dieser Tage den 11. Geburtstag...) ist die Zeit zwischen Weihnachten und Neujahr die Wiege neuer Biblionetzfunktionen. Es ist die Zeit, wo man sich grundsätzliche Gedanken machen, weltfremde Probleme vieldimensional im Kopf wälzen und danach auch noch mehrere Tage und Nächte hintereinander programmieren kann. Naja, zumindest vor 11 Jahren konnte man das, heute siehts auch anders aus und entsprechend wenig wird sich im Biblionetz ändern.
Für diese Festtage habe ich mir eigentlich etwas einfaches vorgenommen: Ich wollte wieder einmal Daten aus der
Computer Science Library importieren.
The DBLP server provides bibliographic information on major computer science journals and proceedings. Initially the server was focused on
DataBase systems and Logic Programming (DBLP), now it is gradually being expanded toward other fields of computer science. You may now read "DBLP" as "Digital Bibliography & Library Project".
The server indexes more than 955000 articles and contains several thousand links to home pages of computer scientists (November 2007).
Diese bibliographischen Daten lassen sich u.a. als
420 MByte grosse XML-Datei herunterladen, ein gefundenes Fressen also, um sich mit der Datenextraktion aus XML-Strukturen zu beschäftigen (das ist Weiterbildung und Rätselspass in einem). Als erstes ist also eine Einarbeitung in
XPath (siehe
Wikipedia), einer Abfragesprache für XML-Daten, notwendig.
Gut, theoretisch ist das Konzept verstanden, nun zur Praxis. Eine kurze Recherche führt mich zum auch für Windows verfügbaren Kommandozeilenwerkzeug
xmlstarlet (siehe
Wikipedia), einer am MIT entwickelten Open Source Software. Somit steht das
Herumspielen Einarbeiten in xmlstarlet auf dem Programm.
Ok, auch das ist erledigt, ich scheine die Syntax begriffen zu haben. Na dann, geben wir doch dem Programm die
420 MByte grosse XML-Datei zum Futtern. Wird wohl ein wenig dauern, also einen Kaffee aufgesetzt und etwas Schokolade genascht...
Mehrere praktische Computerstillstände und viele Pralinen später die Erkenntnis:
XML-Tools, welche die zum Frass vorgeworfenen XML-Daten als Baum im Hauptspeicher aufbauen, brauchen viel Speicher. Bei 420 MByte
sehr, sehr viel Speicher. Keine gangbare Lösung, das Problem lässt sich weder durch mehr Pralinen noch durch mehr Speicher wirklich lösen.
Eine weitere Recherche später weiss ich, dass es neben
DOM-orientieren XML-APIs auch
ereignisorientierte XML-APIs gibt, u.a.
Simple API for XML (SAX) (siehe
Wikipedia), die eben nicht die ganze XML-Struktur speicherfressend im Speicher aufzubauen versuchen. Und erstaunlicherweise unterstützt selbst
MS Access 2003 bzw. die entsprechende XML-Bibliothek SAX. Die Einarbeitung in diese MS-Spezifika ist mir dann aber zu mühsam, und so entsteht eine Bastellösung, über deren Details ich mich hier lieber ausschweige.
Danach kommen eigentlich nur noch die üblichen Probleme von Bibliothekaren: Dubletten im Biblionetz, unterschiedliche Schreibweisen von Personennamen und Sonderzeichen in allen möglichen Zeichensätzen. Also hier und dort einen Konverter oder Filter geschrieben, der in 80% der Fälle funktioniert und in 20% der Fälle …
Beim Recherchieren bin ich über
http://www.io-port.net/ gestolpert:
Das Informatikportal von FIZ Karlsruhe ermöglicht die einfache und schnelle Recherche in mehr als zwei Millionen Publikationen der Informatik und verwandter Themen. Der Datenbestand ist der umfangreichste seiner Art.
Unter anderem bietet
io-port auch die Volltexte aller
Lecture Notes in Informatics (LNI). Für mich interessant: Alle INFOS und
DelFI-Konferenzbände im Volltext. Leider sind diese Volltexte aber nur für zahlende Universitäten und GI-Mitglieder abrufbar. Tja, und keine der Universitäten, bei denen ich eine virtuelle Identität besitze, scheint bisher eine io-port-Lizenz zu besitzen. Und da ich nicht in Deutschland, sondern in der Schweiz wohne, bin ich nicht GI- sondern SI-Mitglied, und ob ich damit Zugang kriege, muss ich noch abklären.
grummel, die Volltexte sind vorhanden, aber nicht frei verfügbar...
Aus Frust bastel ich mir ein Google-Interface, das mit Hilfe von automatisierten Abfragen bei Google versucht, Volltexte von im Biblionetz eingetragenen wissenschaftlichen Texten zu finden. Auch dies eine 80-20-Lösung: Zwar finde ich damit einige Texte, aber der Code funktioniert nicht vollautomatisch, sondern benötigt meine Hilfe, um den Spreu vom Weizen zu trennen.
Daneben auch normaler Biblionetzkar-Alltag: Organisationen, die ihren Webauftritt überarbeitet haben -
gähn - und dabei -
seufz - alle alten Adressen haben sterben lassen. Prominentes Beispiel diesmal:
scil, swiss centre for innovations in learning: Versucht man einen SCIL-Bericht unter der bisherigen Adresse abzurufen, meint die Website nur:
Sorry. This site does not exist in english.
Das Nichtinformatiker/innen nicht an stabile URLs denken, ist ja noch halbwegs nachvollziehbar. Dass aber Entwickler von Content Management Systemen nicht mal mehr
die Grundideen von HTTP berücksichtigen, ist mir weiterhin unverständlich und bringt mich jedes Mal in Rage.
Die Fehlerseite bei SCIL trägt zwar neckisch den Code
404 im (für Menschen gedachten) Titel der Seite:
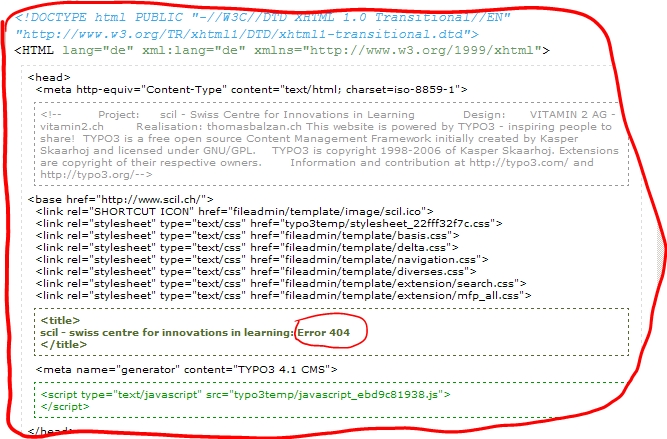
Der Webserver liefert aber den (für Maschinen gedachten) Status
200 OK zurück, so dass Linkchecker nichts davon mitbekommen, dass die Seite gar nicht mehr existiert.
auauaua!

Tja, das führt dann halt dazu, dass Google als ersten Treffer eine Fehlermeldung bringt:
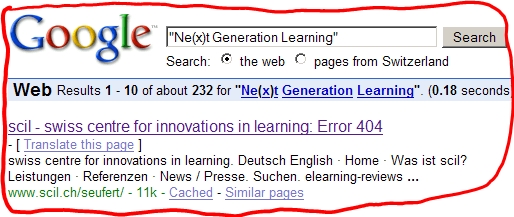 Soviel von der Biblionetz-Entwicklungsfront. Mehr liegt leider dieses Jahr nicht drin. All die anderen lustigen Ideen müssen warten. Mindestens bis nächste Weihnachten.
Soviel von der Biblionetz-Entwicklungsfront. Mehr liegt leider dieses Jahr nicht drin. All die anderen lustigen Ideen müssen warten. Mindestens bis nächste Weihnachten.